cv_笔记
Week 1
lecture 2
Image representation
- Image function
- Landscape
- Array of pixels
- Image histogram
Image transformations
g (x,y) = f (x,y) + 20
g (x,y) = f (-x,y)
Image Arithmetic
Addition : I3(x,y) = I1(x,y) + I2(x,y) 会变得更亮,降噪
Subtraction : Static background, detects change, Object, shadows &
reflections in realworld scenes
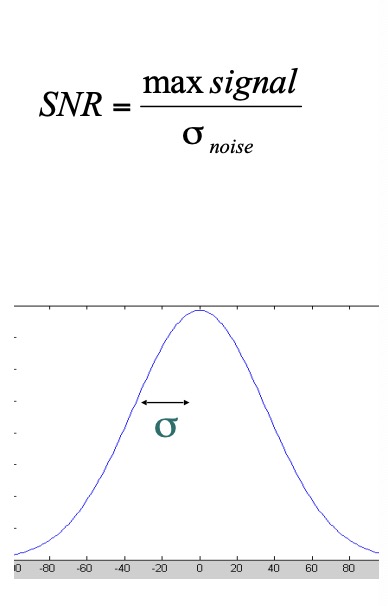
Signal to Noise Ratio (SNR)
较高的 SNR 表示图像包含更多有用的信息和较少的噪声,而较低的 SNR 表示图像的噪声较多且有用性较低。
reduce noise
- temporal averaging : 平均9个图片
- spatial averaging : 九宫格中间的像素平均九个的像素
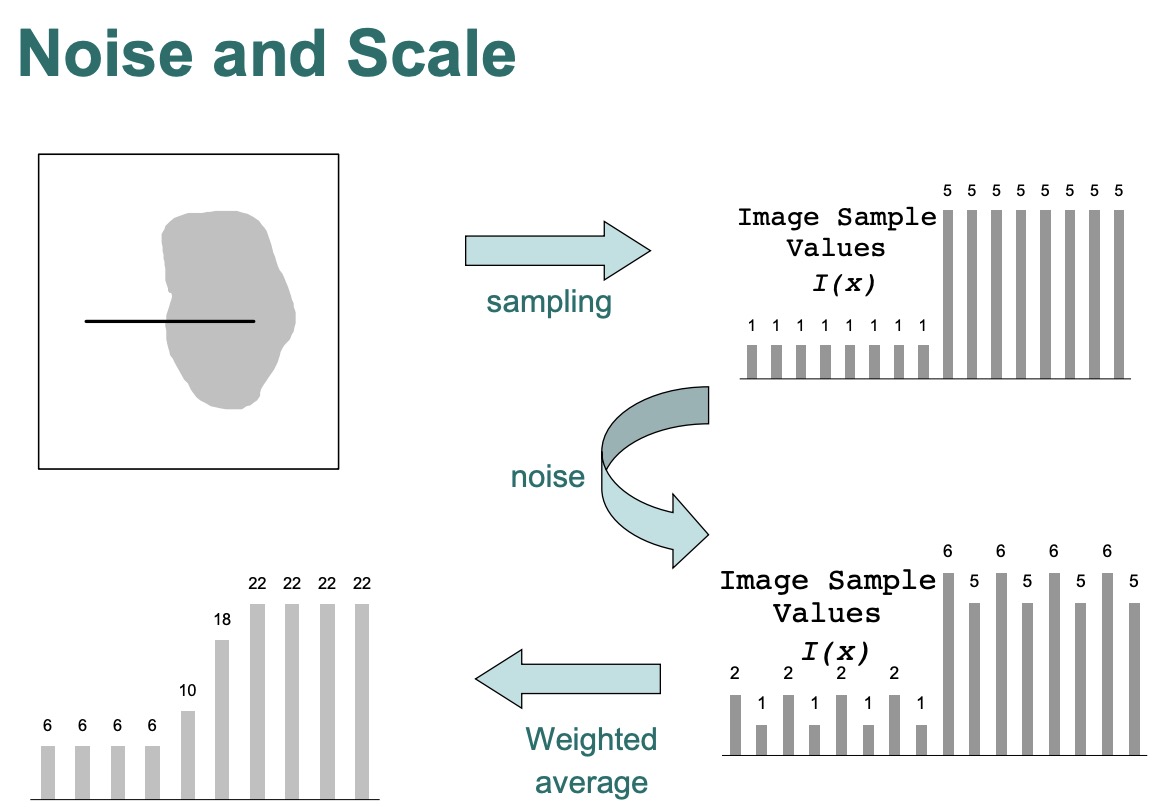
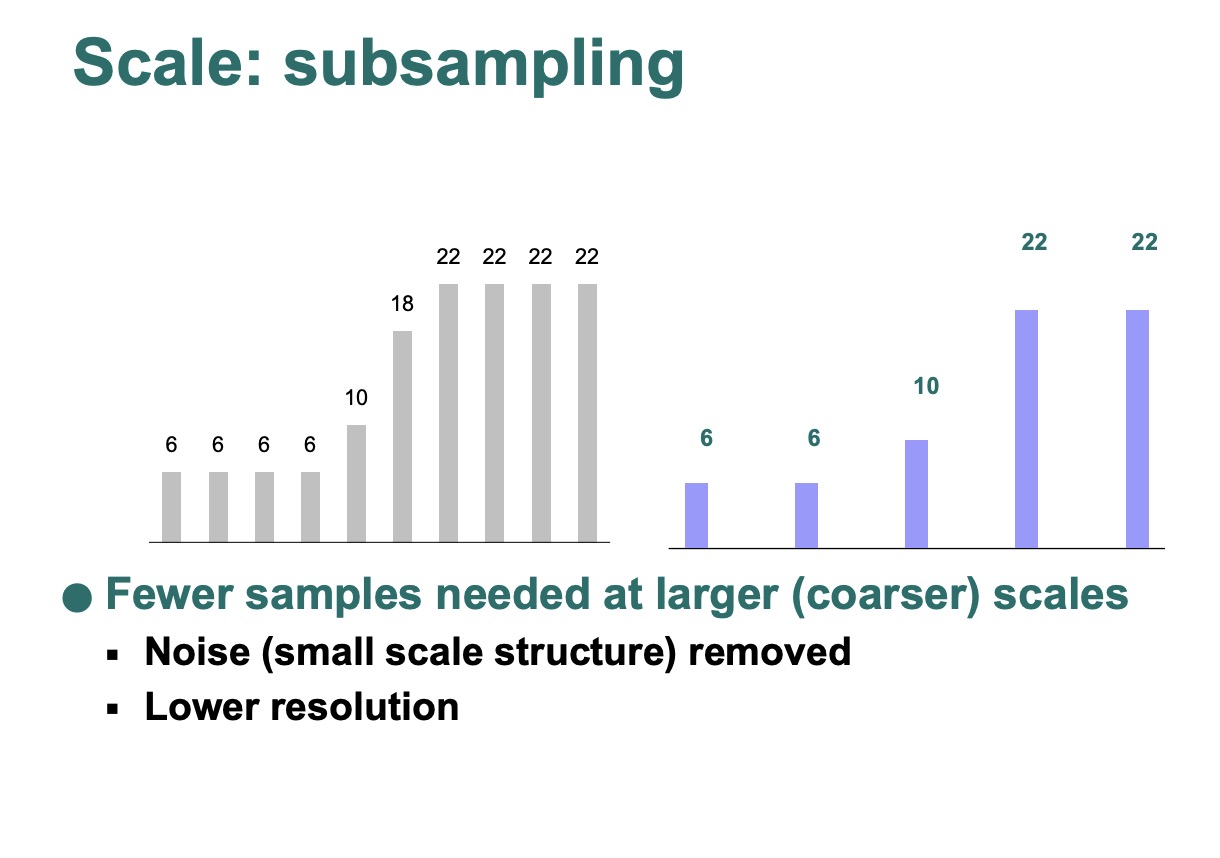
noise & scale
- 降噪会失去small-scale
- noise是我们不想要的small-scale
- 如果最小的scale被移除,我们可以subsample分辨率或者用更少的pixel来表示图像
lecture 3
week 2
edge
- it’s a curve
- depth discontinuity
- surface color discontinuity
- illumination discontinuity
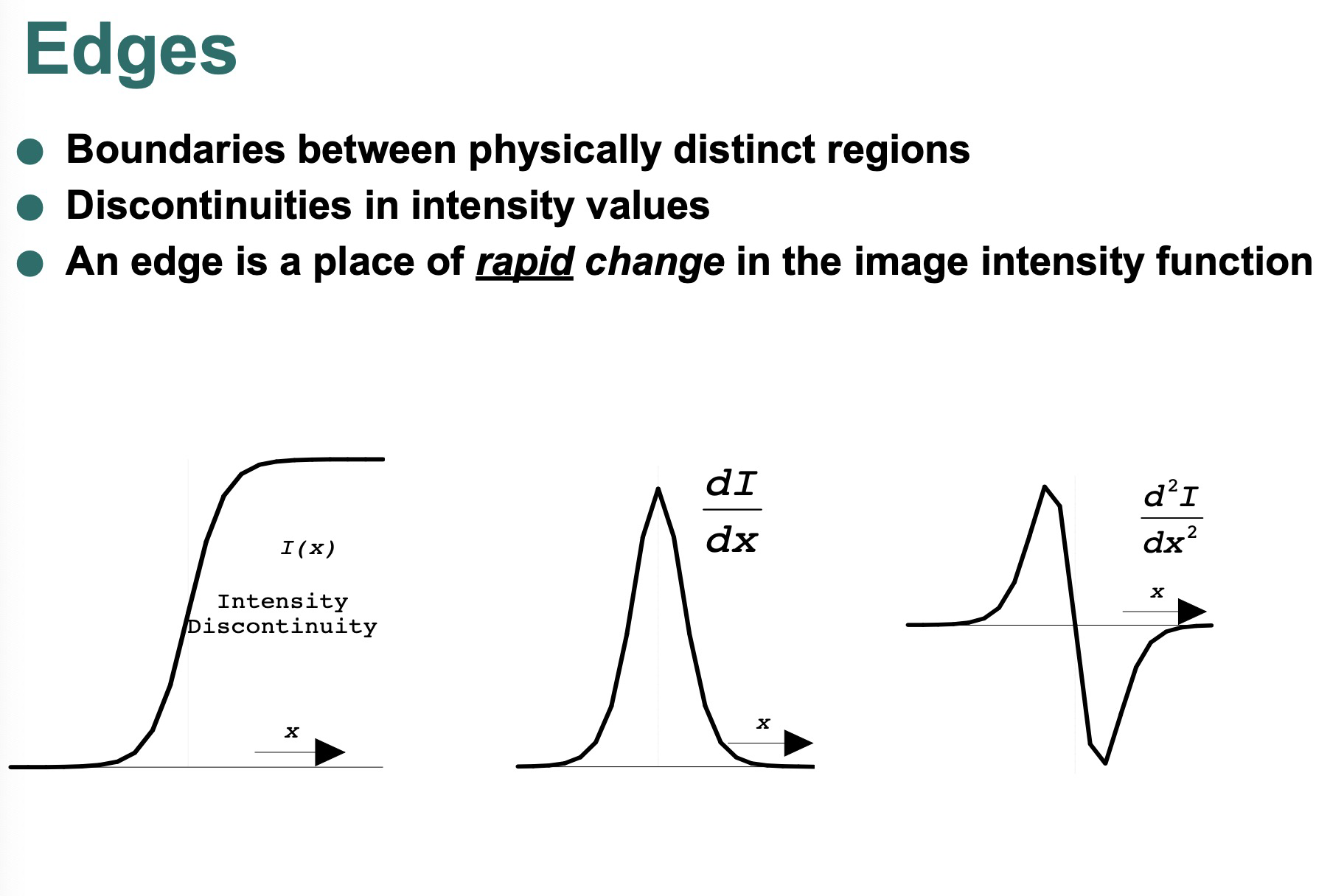
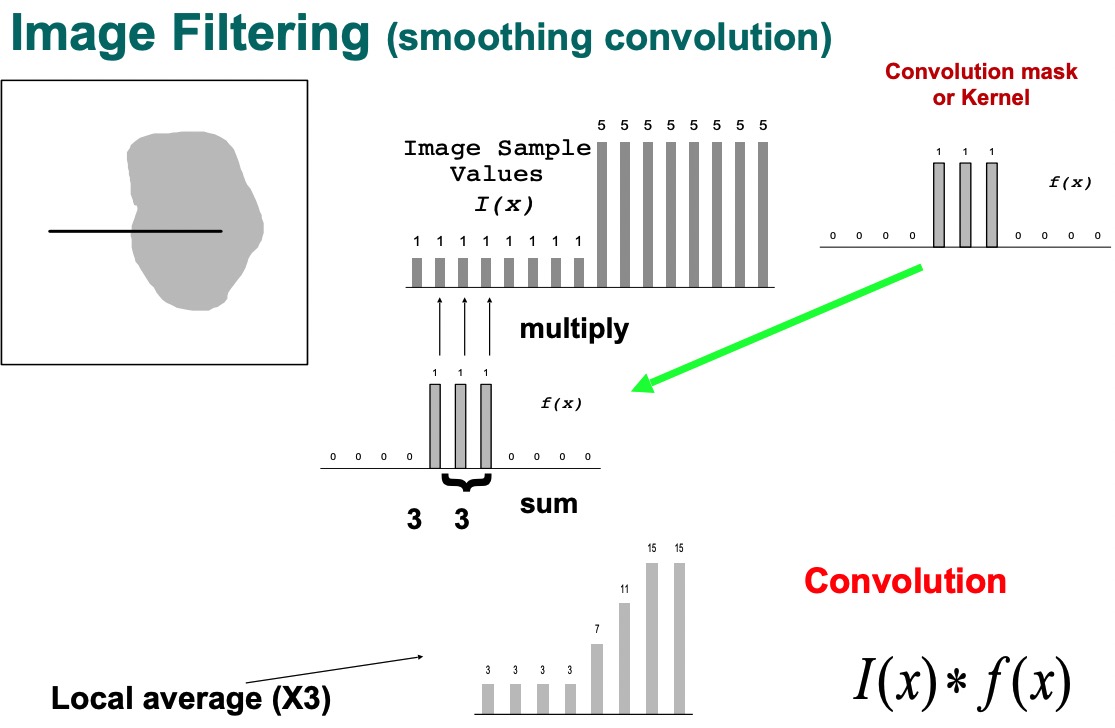
用一条横切线,来寻找几个边界。和右图一样。

$I(x) * F(x)$
Smoothing
- 降噪
- find details,subsampling
*result: big structure of the image , return edges
- form : 00001210000
scale
- 细小的边缘可能只是 “噪音”(无关紧要的小尺度结构)。我们只需要outline。
- 较大尺度的边缘的检测更可靠,因为混乱的细节较少。
- 粗尺边缘(coarse scale)的位置可以指导对细尺度边缘的搜索。更精细的边缘。更快、更稳健。
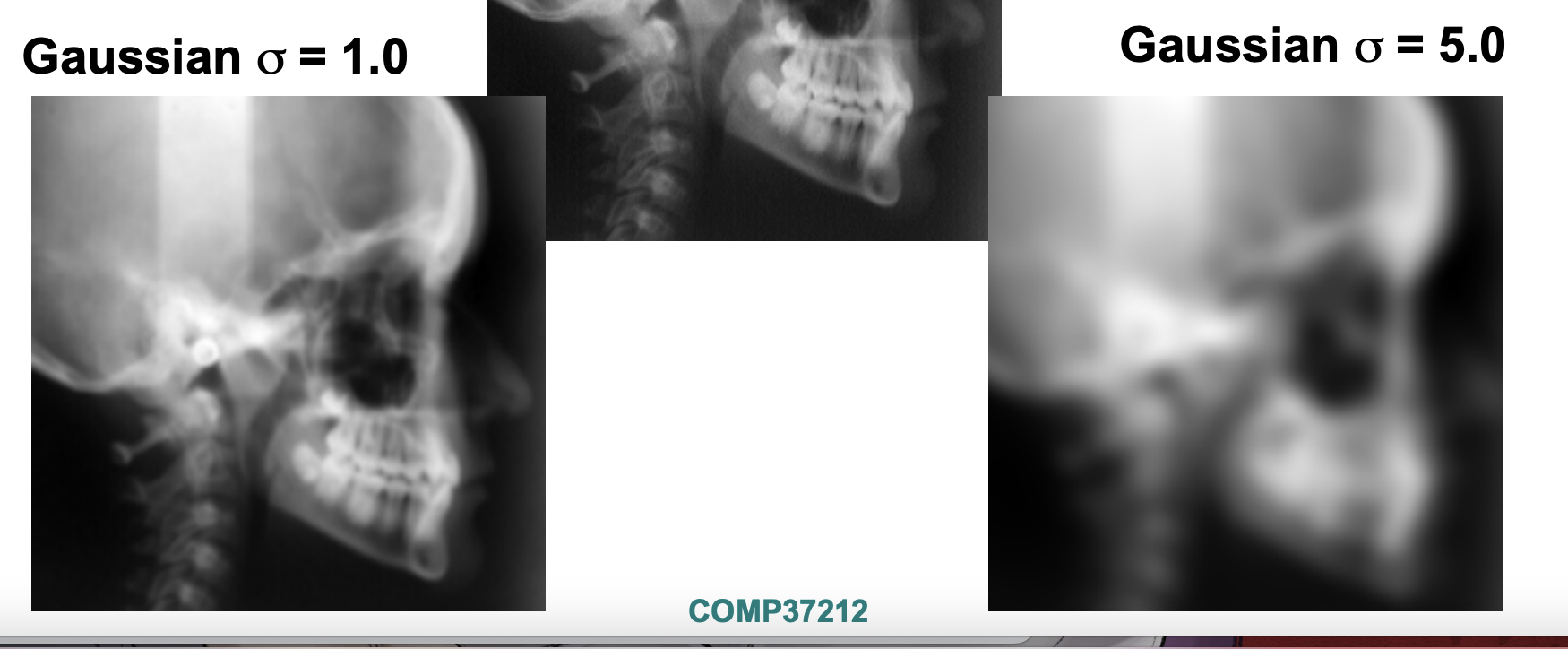
scale effect
- $\sigma$ small , middle of kernel is small
- $\sigma$ bigger , take from a larger area(更boarder), smoothing lot more. bigger structure, bigger edges.

≈
Canny Edge Detector
Week 3
Hough Lines
Cartesian coordinates
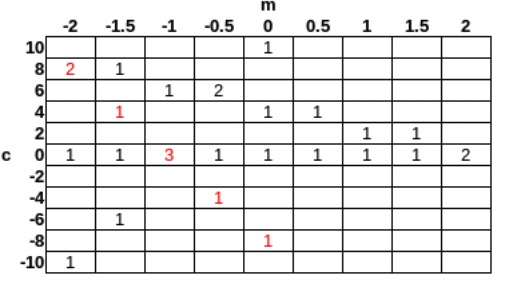
- y = mx + c -> c = -xm + y
- (0,0) , (10,10) -> c = 10m + 10
- 把所有线用c和m表示出来,threshold>=3 的话,经过3个点的那个点m = -1,c = 0. 所以y=-x
What if a line in our image is vertical? m = 正无穷
如果有线是vertical,m无限大,所以用Polar coordiates。
Polar cooridates
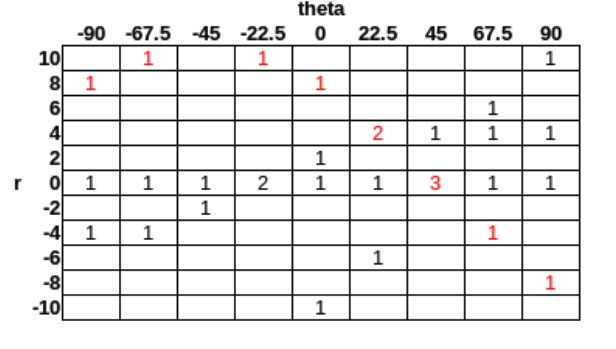
Point (0, 0), r = 0 cos(θ) + 0 sin(θ) = 0
Hough Circles
求到点之后, (a − x)^2 + (b − y)^2 = r^2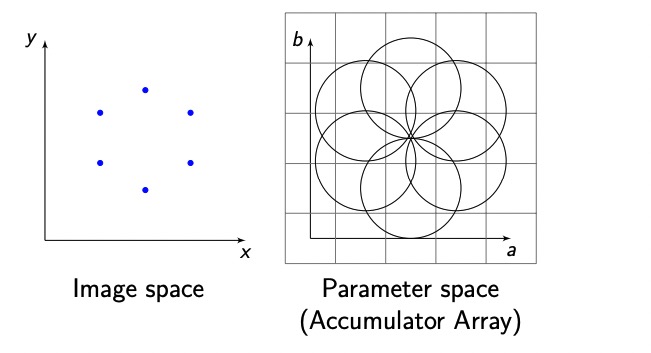
A(Xc,Yc,s,$\theta$)
Generalised Hough Transform
它还可以检测除了圆和线以外的形状
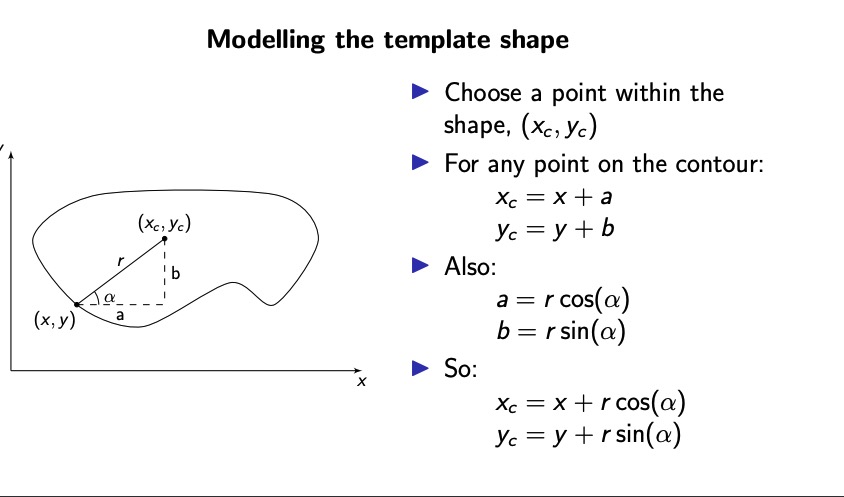
xc = x + r cos(α)
yc = y + r sin(α)
Week 2
edges
edges caused by
- depth discontinuity 深度不连续
- surface colour discontinuity 表面颜色不连续
- illumination discontinuity 光照不连续
积分用来找edge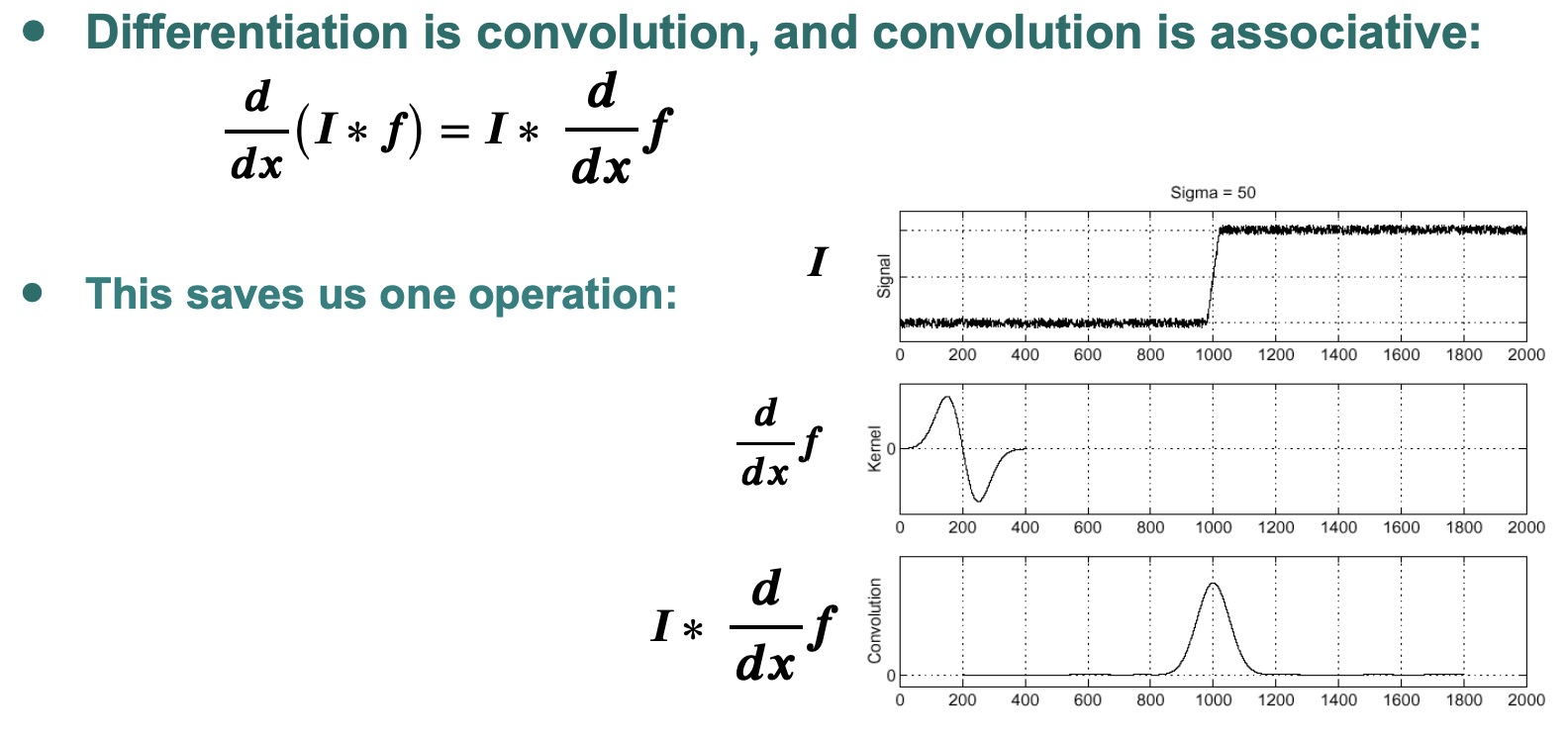
kernels
Prewitt Kernel
vertical edges
-1 0 1
-1 0 1
-1 0 1
horizontal edges
-1 -1 -1
0 0 0
1 1 1
Sobel Kernel
加了一个权重
vertical edges
-1 0 1
-2 0 2
-1 0 1
horizontal edges
-1 2 -1
0 0 0
1 2 1
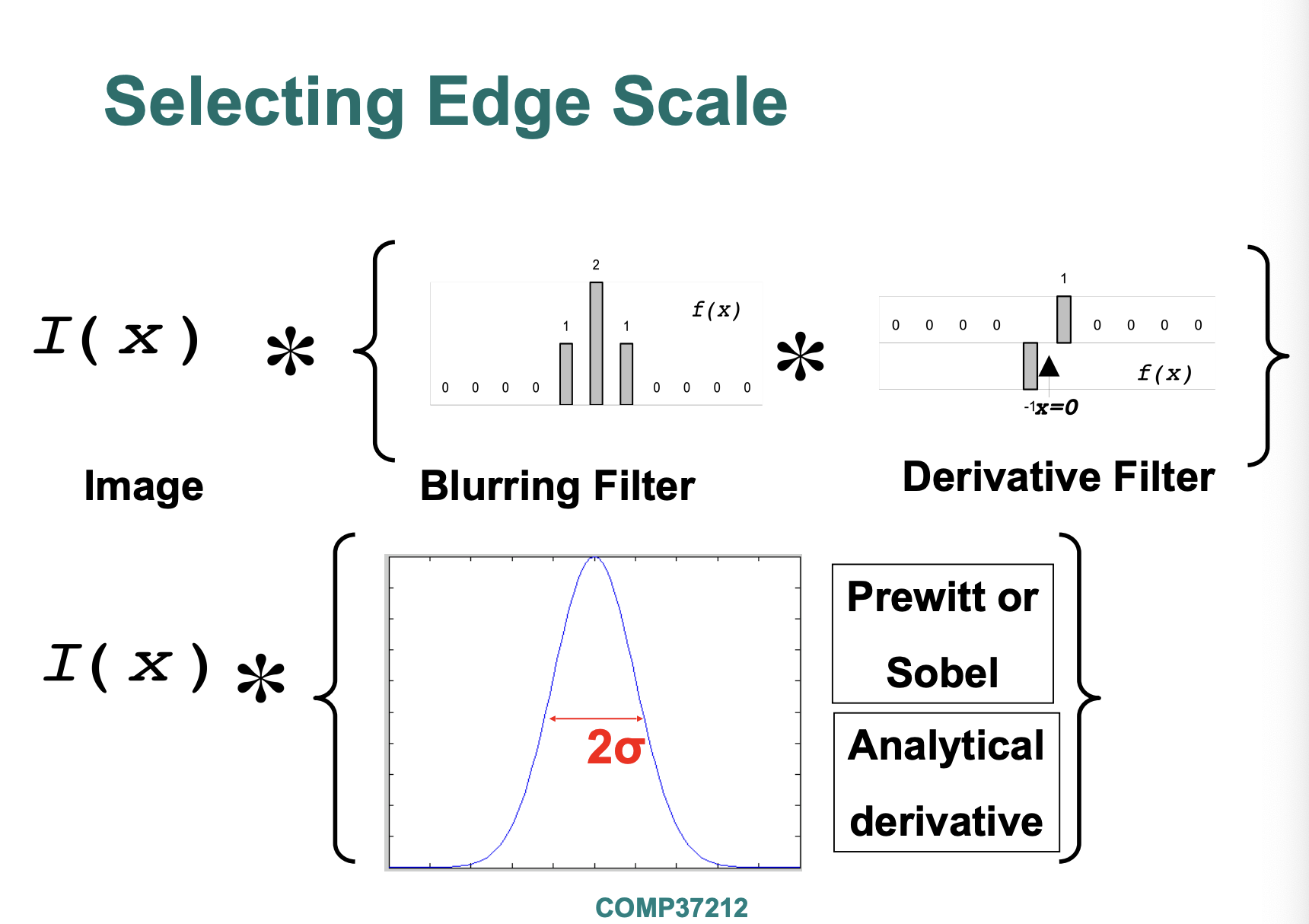
Selecting Edge Scale
■ Edge detection at selected scale
高斯模糊
■ Derivative of Gaussian filter
■ Laplacian of Gaussian
week4
Univariate Normal (Gaussian) Distribution(单变量正太分布)
A normal distribution is not good enough! Need a way to make more complex distributions
Multivariate Normal Distribution (多变量正态分布)
Mixture of Gaussians(MoG) vs EM
优点
- Probabilistic Interpretation: MoG 有a data point belonging to each cluster每个数据点分配一个聚类。
- Soft Assignments: MoG 点是以概率分配给每个cluster的,如果有的点在cluster是不确定的,这是很有用的。
- Generative Model: 不仅建模一存在数据,也创建新的数据点。
- Relatively Compact Storage: GMM 存放紧凑。
缺点
- Local Minima: 他保证了收敛性,
Week 6
Window Function:
1 in window , 0 outside window
Shifted Intensity:
Intensity:
$E(u, v) ≈ [u,v] M [u]^T\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ [v]$
其中M是一个2x2矩阵,被称为结构张量或第二矩矩阵,由图像梯度组成:
$M = ∑_{x, y} w(x, y) * [Ix^2, IxIy \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ IxIy, Iy^2]$
这里,Ix和Iy分别是图像强度在x和y方向的偏导数。
这种提法简化了原来的变化度量,并使哈里斯角落检测器的计算效率提高,使其能够快速识别图像中的角落。
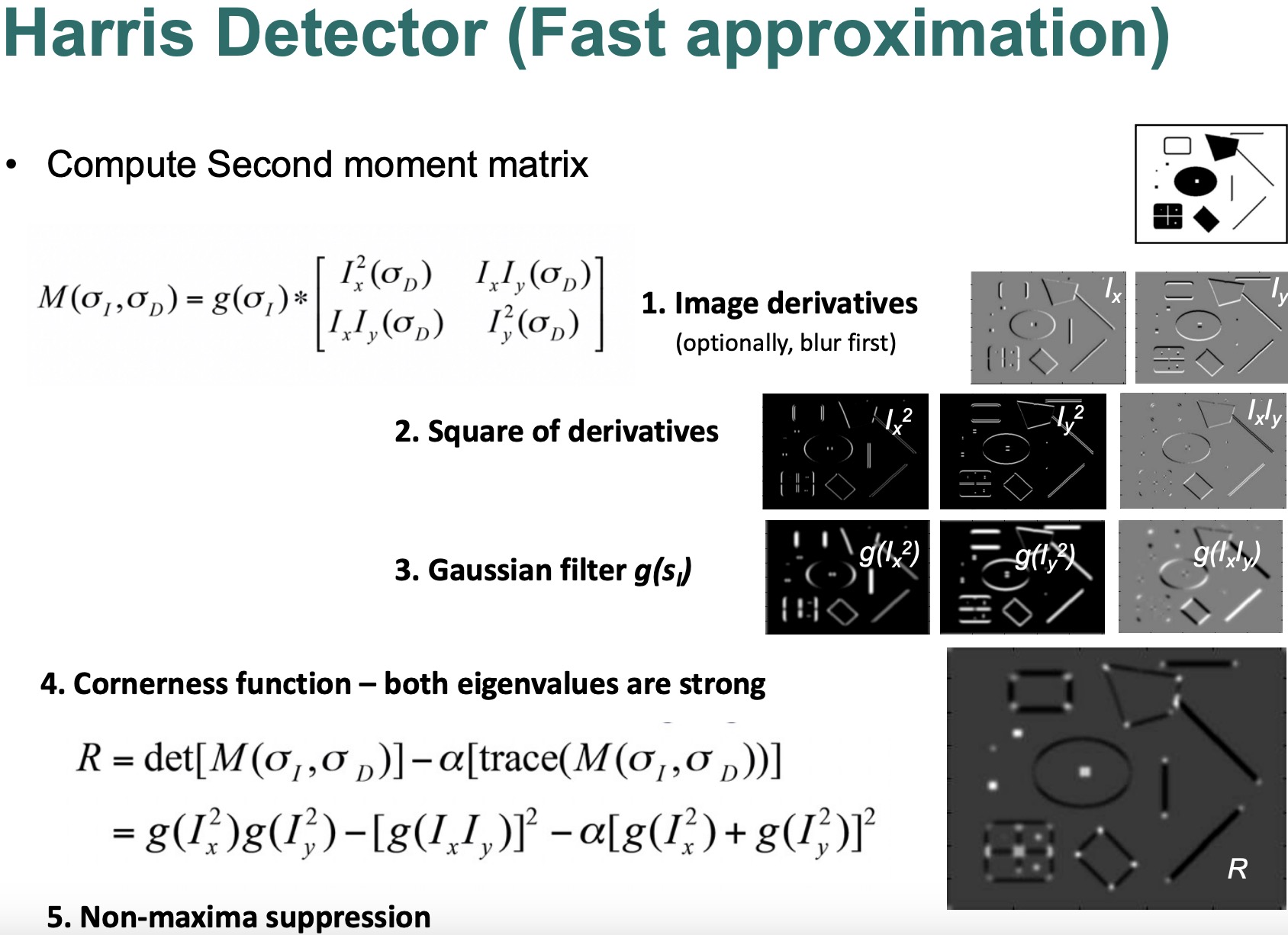
Harris 特点: defines interest points. Precise localization ,High repeatability.
Scale Invariant Region Selection : 两个相同大小不同的物体,他们的特征是一样的。
Automatic Scale Selection : 选择对某一特定特征提供最有用或最独特信息的比例。
Difference-of-Gaussian (DoG) Detector : feature detection algorithm。
Naïve Approach: Exhaustive Search (朴素方法:穷举搜索)
Multi-scale procedure: 从大到小逐渐搜索,先搜索全地图,在搜索房子,然后人。
Compare descriptors while varying the patch size: 局部的前一点。
Computationally inefficient: 消耗了大量的算力。
Inefficient but possible for matching: 效率不高但也可以用。
Prohibitive for retrieval in large databases: 大型数据中检索不利。
Prohibitive for recognition: 识别不利。
Automatic Scale Selection (自动比例选择)
意思就是mulit-scale procedure 的具体确定。
Scale Invariant Function: 这个函数对两个不同比例但相同的图像会给定相同的输出。
Function of Region Size: 一个函数,它的输出是一个区域的大小。
Take a Local Maximum: auto scale selection 的最后一步,找到最大值。
Normalize/ Rescale: 找到了最佳比例后,图像中周围的点都是一个固定的比例,使得目标点可以更好的比较。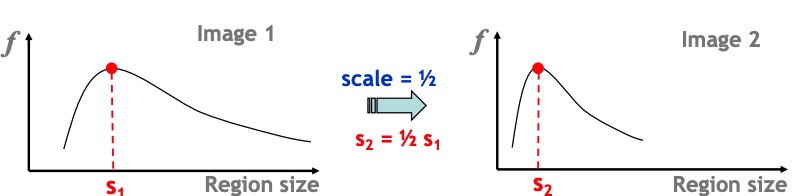
Scale Signature: 一个函数,描述的是图像中特定特征的意义,应该是稳健的,不被噪声或者微小变化干扰的,并且高效的。
Laplacian of an Image
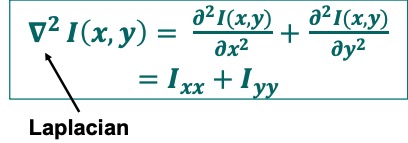
sobel专注于梯度变化,对噪声的抵抗力相对较强,使它适合于高对比度的边缘。laplacian关注二阶导数变化,可以捕捉到sobel检测器可能错过的edge,但对噪声更敏感, laplacian 能够检测到强度在两个方向上都有变化的地方的边缘(比如从暗到亮再到暗的地方)。
Laplacian of Gaussian, LOG
很好的signature, 善于识别图像中的blob。
- Gaussian filter smooth the image.
- Compute the Laplacian of the smoothed image.
- LoG高的地方是blob的中心。
Harris-Lapace method
一种feature detector
- init, 用harris来寻找corner。
- Laplacian 来选择scale。
- 用DoG替代LoG, 加速实现。LoG很昂贵,用Dos替代。
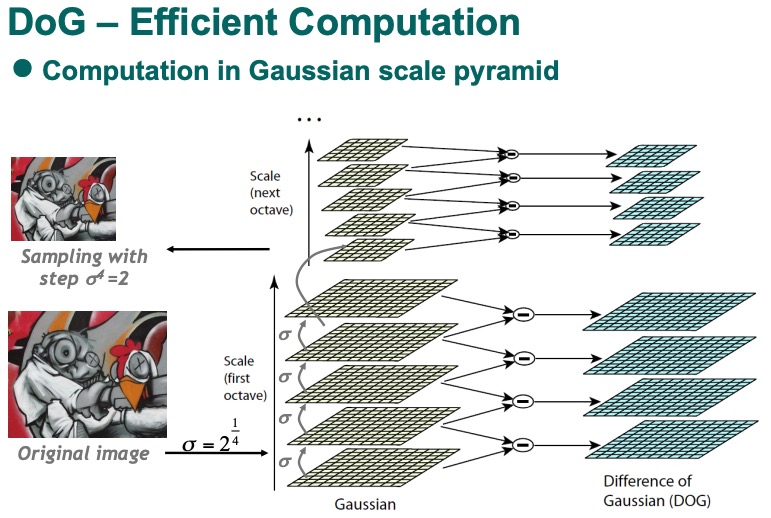
Difference-of-Gaussian DOG
SIFT 等feature detecotor的基础。
- 不需要二阶导。
- Gassian 都要计算的无论如何,所以如果有Gaussian pyramid, 计算DoG的基本数据已经有了,会更加快。 在高斯比例金字塔中,原始图像被递归地缩小,每次都被高斯滤波器平滑化。然后在金字塔中每一对相邻的平滑图像之间计算DoG。
该算法在比例空间中搜索DoG的局部最大值以检测潜在的关键点或兴趣点。在检测到潜在的关键点后,它应用两个过滤器:
低对比度阈值: 该算法放弃了对比度低于某个阈值的关键点。这有助于减少噪声的影响。
边缘响应消除: 该算法还抛弃了位于边缘的关键点。这是因为DoG对边缘很敏感,会产生假阳性反应。
更简单地说,哈里斯-拉普拉斯方法首先在不同的缩放级别上寻找角落,然后利用拉普拉斯选择每个角落的最佳缩放级别。然后,它使用高斯之差,如果你使用的是高斯金字塔,它的计算速度更快,而且已经是这个过程的一部分,来寻找图像中的关键点。该方法可以过滤掉对比度太低的点或位于边缘的点,以确保有一套强大的关键点。
summary: Scale Invariant Detection
● 给定: 同一场景的两幅图像,它们之间有很大的比例差异
差异。
目标:在每张图像中独立地找到相同的兴趣点。
● 解决方案: 搜索合适的函数在比例上的最大值
和空间上的适当函数的最大值(在图像上)。
两种策略
拉普拉斯高斯函数(LoG)
高斯之差(DoG)作为一种快速近似方法
这些方法既可以单独使用,也可以与以下方法组合使用单一尺度的关键点检测器(即Harris角落检测器)。
week 7 Local Feature
Feature detection。
- Invariant Detector : 不变的检测器。
- Find interest points : 寻找兴趣点。
- Remove effect of scale : 消除比例影响。
- Invariant descriptor : 不变的描述符,旋转,比例变化不产生影响。
Local Feature
feature detection
Find Local Orientation: 对于一个patch,寻找到他的dominant direction(local orientation).
Rotate Patch According to this angle: 找到angle之后,对他进行旋转,使得他的dominant direction和x轴对齐。
Scale Invariant Feature Transform (SIFT)
SIFT是一种识别关键点的方法,并以一种对比例和旋转不变的方式来描述它们,而且对视角和光照的变化也很稳健。可以处理大角度。
Feature matching
Given a feature in I1, how to find the best match in I2?
- Define distance function that compares two descriptors
- Test all the features in I2, find the one with min distancer
简单方法SSD(f1,f2)
两个描述点之间的平方差和。
更好的匹配: ratio distance = SSD(f1,f2) / SSD(f1’,f2’)
TP 是真正是别的匹配。
FP 是错误匹配的。
最大化TP增加召回率,最小化FP增加精准度之间找到平衡。
Features are used for:
■ Image alignment (e.g., mosaics) 图像对准(例如,马赛克)。
■ 3D reconstruction 三维重建
■ Motion tracking 运动跟踪
■ Object recognition 物体识别
■ Indexing and database retrieval 索引和数据库检索
■ Robot navigation 机器人导航
week 7 part2
Depth with Stereo : 用两个相机来计算深度。用的是triangulation 三角测量法
image I(x,y) Disparity map D(x,y) image I´(x´,y´)
(x´,y´)=(x+D(x,y), y)
Finding Correspoinces: 容易识别的有趣的点。
The Epipolar Constraint: 相机的位置是一致的,用这个来减少搜索空间。
Matching Edges: edges是方便匹配的地方。
Edge Detection: Canny detector. Multiple scale. Accurate.
用edges的优缺点:
代表了重要的结构,数量不多,可以用image feature来验证匹配。
可以准确定位他们。
Multi-scale location。
不是所有的重要结构都在边缘上。
边缘的大小特征可能匹配的不可靠。
近水平的edges不能提供良好的定位。
Moravec Poeratro Detector: 用于寻找corners。
- Non-linear filter
- 5x5
- 不是旋转不变的,倾向于对edges做出强烈反应。
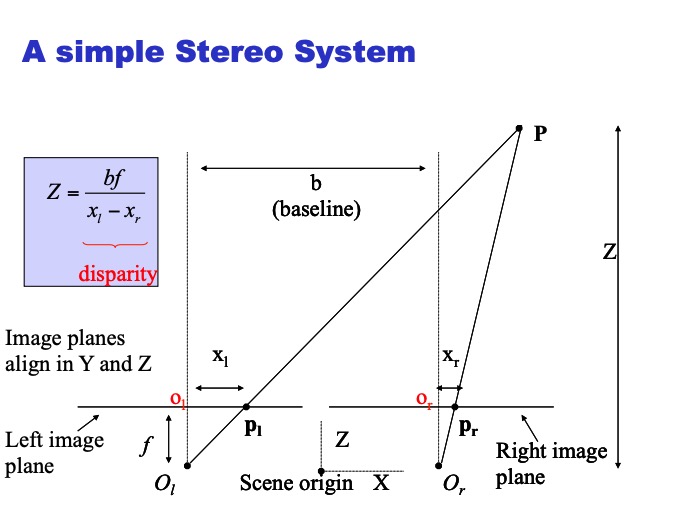
week 8 stereo visiion
part 1
Triangulation: 三角测量法
Epipolar Geometry: 通过这个平面来寻找depth information.
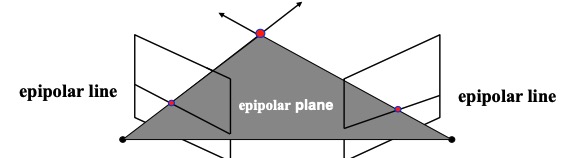
Extrinsic Parameters: 描述相机的姿态。 R T
Epipolar Constraint: 立体图像中的点总是对应epipolar lines。
Epipole: 两个相机的中心点。是所有epipolar lines 的汇聚点。
Disparity: 两个立体图像中的一个点的位置差异。与对应像素的depth成反比。
Rectification: 立体图像的转换过程。
Intrinsic Parameters: focal length, principal point, lens distortion coefficients….
Essential Matrix: 封装了两个相机是图之间的几何形状,translation and rotation 的matrix。
Sterio calibration: 立体校准,评估参数找到Intrinstic 和 extrinstic parameters.
总体步骤:
- stereopsis 提供3D位置的精准测量。
- 需要建立对应关系,比如Epipolar lines, Matching criteria(匹配标准比如edge,corners,interest points), Disparity computation。
- Constraints(Calibration立体校准从而获得内部参数和外部参数)
- Reconstruction by triangulation 三角测量进行三维重组。
part 2
Image Alignment 图像对准
Application: Image Stiching 图像拼接
- Euclidean = (translation + rotation)
- Similarity = (translation + rotation + scaling)
- Affine = (translation + rotation + scaling + shear )
- Projective = (homography)
RANSAC
- Randomly select a minimal set of points. 能适合模型最小的可能大小,比如一条线需要2个点。
- 为这个子集计算模型的参数,比如tranformation
- inliers: 用这个模型来测试所有的数据,如果数据点与模型的距离小于某个阈值,就认为它是一个inlier。
- 把数据分成inliers and outliers, inliers就是好的,outliers就是坏的。
- 如果inliers显著的大,就用inliers重新测量,得到精炼模型。
- 重放1-4次。
- 找到最大inliers的模型作为最终模型。
- 优点在于即使存在大量的outliers,也能找到好的模型。尤其是outliers大于50%的时候,也能通过N来确定模型。
找到这个变换的异常值: 在估计出一个模型后,RANSAC根据所选择的距离度量将其余的数据分类为离群值和异常值。异常值是指与估计模型契合度高的点(即它们与模型的距离低于某个阈值),而异常值则不是。
如果离群点的数量足够大,就在所有离群点上重新计算最小二乘法的变换估计: 如果离群值的数量足够大,RANSAC使用所有离群值重新估计模型参数,并得到一个精炼的模型。
重复N次: 步骤1-4重复N次,N是该算法的一个参数。每次迭代都有可能产生一组不同的异常值和模型参数。
保留具有最大数量离群值的变换: 在所有迭代之后,RANSAC会选择具有最大离群值的模型作为最终模型。
RANSAC的优点在于,即使数据中存在大量的异常值,它也能够找到正确的模型。然而,它并不能保证一个最佳的解决方案,特别是当异常值的比例非常高时(>50%)。迭代次数(N)和确定异常值的阈值是能够影响RANSAC性能的关键参数。
总体步骤
Given two (or more) images:
- Step 1: Detect features, 在全景图像拼接中,通常首选SIFT(尺度不变特征变换)
- Step 2: Match features ssd 或者 ssd1/ssd2
- Step 3: Compute a homography using RANSAC
- Step 4: Combine the images together (image blending) : Iblend = αIleft + (1-α)Iright alpha blending
好的window是什么样的?
avoid seams, avoid ghosting. 避免接缝和重影。
week 9 object recognition with local feature
Indexing with Local Features
Inverted File Index: 倒置文件,一种数据结构,存放着visual features的索引。用于快速检索特定的特征。
Visual Words: SIFT等来识别出的特征corner,edge, blob 等。
Visual Vocabulary Construction : 用k-means来构建visual vocabulary。visual words的集合。
Use for Content-Based Image/Video Retrieval: 一旦我们有了Inverted File Index和Visual Words 我们就可以提取所有视觉词,找到包含相同词的图像或者视频。相同的共同词越多我们约我认为他们相似。
Object Categorization
Object Categorization Revisited: 重新审视物体分类。比如狗,汽车,把检测的物体装进大集合里面。
More Exact Task Definition: 更精准的任务定义。比如给定一个图像,判断它是否包含一个特定的特征,比如颜色,大小。不仅仅是识别物体的类型是什么。
basic Level Catergories: 对物体进行分类,比如狗为一个大类,相对于哺乳动物或者狮子狗来说。
Category Representations: cv中如何表现类别,最常见的是vector of features。每一个特征是类别中的某些方面,比如颜色,形状。
BoG (Bag-of-Words) Representations
BoG Representations: 用于图像分类的一种表示,其中图像被视为单词的集合,而不是像素的集合。这种表示通常用于图像分类,其中图像被视为单词的集合,而不是像素的集合。这种表示通常用于图像分类,其中图像被视为单词的集合,而不是像素的集合。这种表示通常用于图像分类,其中图像被视为单词的集合,而不是像素的集合。这种表示通常用于图像分类,其中图像被视为单词的集合,而不是像素的集合。这种表示通常用于图像分类,其中图像被视为单词的集合,而不是像素的集合。这种表示通常用于图像分类,其中图像被视为单词的集合,而不是像素的集合。这种表示通常用于图像分类,其中图像被视为单词的集合,而不是像素的集合。这种表示通常用于图像分类,其中图像被视为单词的集合,而不是像素的集合。
优点:
- Flexible to geometry/deformations/viewpoint: BoW模型对空间排列不敏感,因此可以处理物体的变形,旋转和不同的视角。
- Compact summary of image content: BoW模型是图像内容的紧凑摘要,因此可以处理大量的图像。
- Povides vector representation for sets: 每幅图像可以被表示为高维空间中的一个向量,其中每个维度都对应着一个 “视觉词”。这允许对图像进行有效的比较和分类。
- 简单且表现良好。
缺点:
- 忽略了geometry,忽略了几何学。重大限制,不过可以在BoW匹配之后执行一个集合验证步骤来解决。
- BoW覆盖整个图像,background和foreground 都被考虑进去了。这可能会导致噪音和不相干的特征被包含在bag中,会导致性能降低。
- Interest Points or sampling: 不能保证物体层面的部分。
- Optimal vocabulary formation remains unclear: 不同方法适用于不同的任务和数据集,没有一个公用的。
Feature Detection Application - Drone Self-localisation
GPS
GPS 问题:
- 复杂地形不行
- GPS容易被spoofing欺骗
- GPS signal blocking 高于卫星信号发射信号防止他们被接收
Face Detection
Decisiion Trees and Random Forest: 构建大量的decision trees,每个tree都是一个分类器,最终结果是所有分类器的投票结果。
AdaBoost : ml算法,结合表现不佳的分类器来构建一个强大的分类器。
Viola-Jones Face Detector: 用于检测人脸的ml算法,基于AdaBoost,通过AdaBoost来提高分类器准确性。
OpenCV: 题哦给你了CascadeClassifer, 可以用来创建Viola-Jones检测器。
LAST DANCE
Hough
- edge detection : canny
- parameter space : (p,theta) 或者 (x,y)
- accumulator space : voting 累积每一个经过的点
- line detection : 投票过的点坐标作为在最终图像中的线。
Generalized Hough Tranform(GHT)
where r is the distance from the reference point to the boundary point and
θ is the angle
一些基本概念:
PCA: 种通过压制较弱的模式来带出数据集中的强势模式的方法,使数据更容易被可视化、理解和被后续算法处理。它通常被用于探索性数据分析和制作预测模型
ASM (Active Shape Model)
物体形状的统计模型,手动标注了地标点,用来构建模型。local feature 猫的耳朵。。。小特征
3D Reconstruction: 三维重建
Image Compositing: 图像合成 , 把两个图像合二为一融合起来。
Segmentation and grouping : 分割是将图像划分为多个片段或 “区域 “的过程,其目的是简 图像和/或将其表现形式改变为更有意义的东西
- Gestalt principles: 花花草草为一组,树木为一组。。。
- Image segmentation: 一般要使用颜色的分割,边缘检测。。。
EM,GM ,K-means: random initialization, 和 K-means++ 两种初始化方法,GMM + EM = 每一个cluster要遵循高斯分布, soft clustering, K-means 反之是hard clustering
Harris vs SIFT
- Scale-Invariance, Harris 在不同尺度下才能显示出的corner Harris发现不了。SIFT通过difference of Gaussian approach 做到了这一点。
- Rotation-Invariance, 物体旋转Harris检测不出,SIFT可以
- descriptor, harris自己是没有descriptor的需要结合别的方法,他只有keypoints。
- SIFT耗时久,如果只关注corner或者需要高效,Harris是个好选择。
- Harris: 使用图像强度的二阶导数矩阵来观察每个像素周围的图像局部结构。这个矩阵的特征值给出了图像中该点的边缘或角落的强度的测量,这个矩阵被用来创建一个触发角落的响应函数。
- SIFT:
- Contrast threshold: 一个过滤器,删除那些由于对比度低而不太可能被正确匹配的点。
- Curvature Threshold: 消除具有高边缘响应的关键点。这是因为边缘往往可以有很高的对比度。该算法可以将重点放在角落、大块和其他更有可能被稳健匹配的区域。
- Dimensionality of Feature vector: SIFT中特征向量的维度是指为每个关键点创建的方向直方图中的宾格数量。这些方向直方图代表了关键点周围不同子区域的梯度(即方向)分布。
- steps:
- scale-space extrema detection: 通过scale-space pyramid 寻找intrest points
- keypoint localization: 通过两个threshold减少第一步选择的keypoints。
- give an orientation to the keypoints.
- keypoint descriptor: 表示为一个vector。
BoW(Bag of Words):
- Feature extraction(特征提取): SIFT, ORB….
- Clustering: k-means, GMM … ,每一个cluster都是一个visual words
- Histogram creation: 每一个 visual words的出现频率
- Naive Bayes classifier:
Image Alignment 图像对准 Application: Image Stiching
- Camera calibration : Extrinsic parameters(Rotate matrix ,Translate Vector). ntrinsic parameters(focal length, original offset(原点偏移), Pixel size(像素大小))
- Feature extraction and matching: SIFT….
- Rectification: 对其两张图像,相同的点位于同一水平线上
- Disparity computation :两张图片找到差异的点,作为x移动的坐标
- Depth estimation:用disparities三角测量,来算每个点的深度Z = fB/d。
Stereo:
- Window Size, 小只能包含像素差异,大会包含区域差异。
- sparse, 只考虑部分特征,比如SIFT。需要方法确定哪些特征是重要或者相关的。
- dense, 用每个像素点来计算,但是计算量大,三维重建游泳,缺乏纹理或者细节区域效果不好。图像视角非常不同的时候,dense也不能用。